
Biblioteka graficzna
Istotnym elementem systemu posiadającego GUI jest biblioteka graficzna. Nie sposób bowiem wymagać od każdej aplikacji, każdego komponentu aby samodzielnie “sięgał” do wyświetlacza i mozolnie rysował na nim piksel po pikselu. Absolutnie podstawową funkcjonalność stanowią tzw. prymitywy graficzne – punkty, linie czy okręgi. Kolejnym krokiem są figury składające się z linii: prostokąty, trójkąty – ogólnie mówiąc wieloboki. Odrębną kategorię stanowią metody służące do rysowania tekstu, zazwyczaj wykorzystujące do tego celu predefiniowane fonty.
Tego typu funkcjonalność oferuje zdecydowana większość dostępnych bibliotek graficznych dla systemów embedded, takich jak AdafruitGFX, TFT library czy MBED. Nierzadko implementowane są również bardziej zaawansowane, wysokopoziomowe elementy GUI jak przyciski, checkboxy, listy, pola tekstowe, etc.
Jednak mimo tak szerokiego wachlarza dostępnych bibliotek, postanowiłem stworzyć od zera własną.
Dlaczego? Jaki sens ma wynajdywanie koła na nowo?
Na pozór gotowa biblioteka wydaje się być idealnym rozwiązaniem. Nie wymaga inwestycji cennego czasu, zapewnia kompletną funkcjonalność, jest dobrze przetestowana – same superlatywy.
Jeśli jednak przyjrzeć się bliżej, zaczniemy dostrzegać pewne niedogodności. Przede wszystkim każda z w/w bibliotek jest w pewnym stopniu uzależniona od hardware’u, na który pierwotnie została napisana. Dodatkowo biblioteki te dostarczają kod zoptymalizowany pod kątem danego wyświetlacza, który “sprytnie” korzysta z dostępnego interfejsu sprzętowego czy możliwości sterownika LCD.
Innymi słowy – stanowią one połączenie biblioteki graficznej, drivera sprzętowego i warstwy abstrakcji. Tego typu mieszanka ma dwie, ogromne wady – całkowity brak przenośności między platformami i uzależnienie od jednego, konkretnego modelu wyświetlacza LCD.
Jaka powinna więc być “idealna” biblioteka?
Krótko? Coś takiego po prostu nie istnieje 🙂 Dobrym początkiem, byłaby próba rozdzielenia biblioteki oraz drivera samego wyświetlacza. Wówczas logiczna struktura prezentowałaby się następująco:
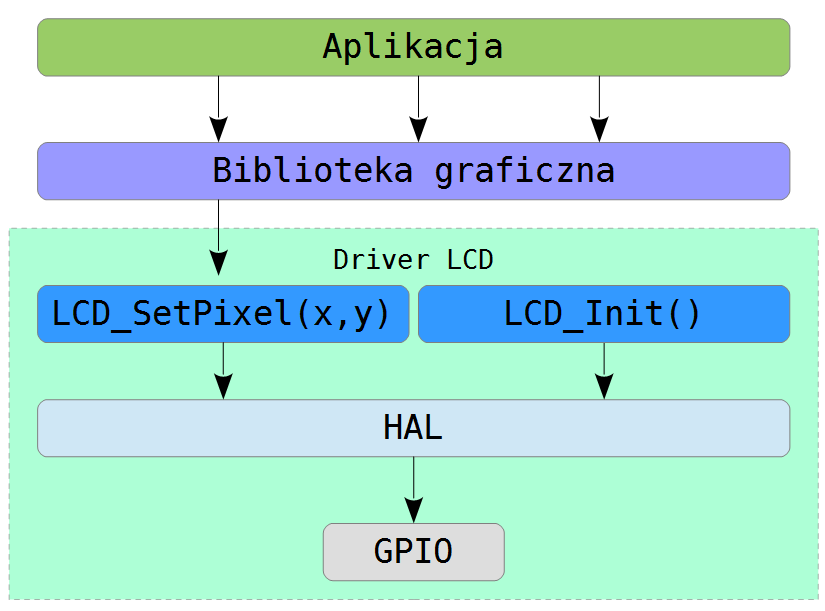
Oczywiście wiele osób słusznie zarzuci mi w tym momencie, iż takie rozwiązanie jest mocno nieoptymalne. Ma jednak dwie, ogromne zalety – elastyczność i prostotę, wynikające z całkowitego odseparowania warstwy czysto software’owej (biblioteki graficznej) od warstwy sterującej sprzętem (driver). Wszelkie interakcje między nimi prowadzone są tylko i wyłącznie za pomocną zdefiniowanego interfejsu. I to on stanowi kluczową część…
Ok, więc jaki powinien być “idealny” interfejs?
Tu akurat można udzielić precyzyjnej odpowiedzi. Zazwyczaj za dobrze skonstruowany interfejs, uważa się taki, który przy najmniejszej liczbie funkcji zapewnia kompletność oraz jest pozbawiony jawnych bądź ukrytych zależności do zewnętrznych komponentów. W przypadku grafiki trudno wyobrazić sobie interfejs bardziej minimalistyczny i abstrakcyjny niż po prostu “ustaw piksel” 🙂
Co zyskujemy?
Załóżmy, iż zmieniamy sposób sterowania wyświetlaczem na port szeregowy SPI. Cały driver oraz warstwa abstrakcji sprzętu ulega zmianie. W przypadku, w którym byłyby one częścią składową samej biblioteki, musielibyśmy przepisać także części jej funkcji. W zaproponowanym rozwiązaniu wszelkie zmiany kończą się na poziomie wspomnianego interfejsu.
Podsumowanie
Na tak błahym i trywialnym w gruncie rzeczy przykładzie jak rysowanie kółek i linii widzimy, iż tworzenie oprogramowania jest zawsze sztuką kompromisów. W tym konkretnym przypadku musieliśmy wybrać między rozwiązaniem zoptymalizowanym – pozornie lepszym, a opcją wolniejszą, która jednak zapewnia o wiele większą elastyczność. Biorąc pod uwagę, iż projekt wciąż się rozwija i zmienia, bardziej perspektywiczne jest więc użycie tej drugiej. Mimo wszystkich swych wad jest podatna na zmiany i łatwa do zaadaptowania.
Poszukiwanie już na początkowym etapie mocno zoptymalizowanych rozwiązań, skutecznie ogranicza możliwości rozbudowy oprogramowania i zamyka przed nami wiele dróg rozwoju. Takie postępowanie nazywane jest przedwczesną optymalizacją (ang. premature optimization) i jest często popełnianym błędem, zwłaszcza wśród początkujących developerów. Wynika ono z przeświadczenia, iż dany komponent uzyskał już swoją ostateczną formę i należy skupić się na aspektach związanych z wydajnością.
Drugim błędem, który jako developerzy często popełniamy jest mieszanie ze sobą “warstw” oprogramowania. Prowadzi to do powstawania niespójnych interfejsów oraz ukrytych zależności. Temat ten poruszałem już wcześniej, w rozważaniach na temat warstwy abstrakcji sprzętu. Dziś pojawił się on ponownie, tym razem w świecie grafiki i zapewne pojawi się jeszcze nie raz. Świadczy to tylko o tym, jak istotną kwestią jest poprawne zaplanowanie struktury oprogramowania.
Dlatego też w niedalekiej przyszłości chciałbym poruszyć oba tematy ponownie, jednak w odrębnym artykule – zdecydowanie na to zasługują 🙂
Na dziś tyle..
Hola hola, a gdzie jakieś kolorki? Hmm?
Ano tak – byłbym zapomniał. Z racji iż mamy Święta Wielkanocne będzie coś w klimacie 🙂

