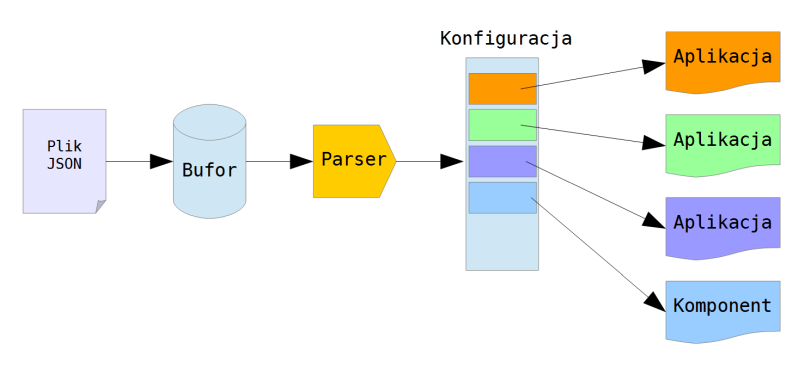
Dziś na moment ponownie powrócimy do tematu konfiguracji. Jak pamiętacie z poprzednich artykułów, zdecydowaliśmy się przechowywać całą konfigurację w formie pliku JSON na karcie pamięci. Udało się także stworzyć odpowiedni parser, którego zadaniem będzie przetłumaczenie tekstowego formatu pliku JSON na binarną strukturę, zrozumiałą dla naszych aplikacji. Spróbujmy zastanowić się jak powinien wyglądać przepływ informacji: od pliku na karcie SD aż do momentu zaaplikowania konfiguracji w określonych komponentach systemu.
Samo wczytanie pliku JSON z karty pamięci nie nastręcza szczególnych trudności – wykorzystamy w tym celu driver FatFs. Ale co dalej?
Napisany na potrzeby projektu parser formatu JSON oczekuje na swoim wejściu tekstu (ściślej: wskaźnika na tablicę znaków – takie ekstra info dla nerdów 😀 ). Naturalnym rozwiązaniem wydaje się zastosowanie jakiegoś bufora, do którego wstępnie wczytamy cały plik konfiguracyjny. Następnie tak przygotowany bufor przekażemy parserowi.
Hm… Po co tracić czas i miejsce w pamięci na buforowanie danych? Przecież parser może wczytywać tekst bezpośrednio z pliku.
Owszem, może – jednak na pewno nie będzie to rozwiazanie szybsze.
Dlaczego?
Parser interpretuje tekst znak po znaku, co oznacza, jednorazowo wczytywałby jeden lub dwa bajty (kodowanie UTF/Unicode) z pliku. Każde żądanie odczytu danych z karty wymaga odwołania się do interfejsu SDIO i poczekania aż karta odpowie paczką danych. Powstaje więc ogromny narzut danych kontrolnych w stosunku do liczby faktycznie odczytanych bajtów. Dodatkowo należy pamiętać, iż karty SD są najefektywniejsze (czyli najszybsze) w trybie pakietowego strumieniowania danych, kiedy odczytywany jest długi, ciągły fragment pamięci. W takim przypadku narzut operacji kontrolnych jest minimalny, a realna prędkość odczytu ograniczona jedynie przez przepustowość interfejsu SDIO oraz możliwości (klasę) samej karty.
Ok, ale nadal marnujemy spory kawałek cennej pamięci RAM na bufor…
Po pierwsze pamięć ta może zostać zwolniona po wykonaniu operacji parsowania i użyta ponownie przez inne aplikacje. Po drugie, wyodrębnienie mechanizmu buforującego zawartość pliku w pamięci wydaje się być dobrym kandydatem na kawałek kodu, który może nam się przydać ponownie w przyszłości. Przemawiają za nim: uniwersalny interfejs oraz ściśle określone zadanie, które ma wykonywać. Ponadto w myśl reguły DRY, każdy dobrze zdefiniowany fragment kod, tworzący kompletną, odrębną funkcjonalność warto wyekstrahować w formie biblioteki/funkcji/komponentu.
Idźmy krok dalej – parser przetłumaczył tekst na strukturę binarną. Co się z nią stanie później?
Sam format JSON wymusza pewną hierarchiczną strukturę danych. Poszczególne zestawy parametrów mogą zostać pogrupowane i przypisane do nadrzędnych struktur, a te z kolei staną się składowymi kolejnych struktur, itd itd itd. Oczywiście można także rozpatrywać “płaską” strukturę parametrów, bez żadnej hierarchii, jednak taka forma pliku będzie bardzo nieczytelna dla człowieka. Ponadto istotnym problemem będzie stworzenie tak dużej ilości unikalnych nazw dla każdego z parametrów.
Jak więc powinna wyglądać taka struktura?
Wyobraźmy sobie, że chcemy przechowywać czas, po jakim zadziała asystent przypominający o odpoczynku kierowcy. Nazwijmy ten parametr czasDoOdpoczynku. Naturalnie jest on parametrem, który przynależy tylko i wyłącznie do asystenta odpoczynku – można więc przypisać go do struktury asystentOdpoczynku. Ponieważ w systemie istnieje kilku asystentów, można utworzyć strukturę nadrzędną o nazwie asystenci.
Aby lepiej zobrazować tą ideę, poniżej przedstawiam przykładową strukturę takiej konfiguracji:
- konfiguracja
- asystenci
- asystentOdpoczynku
- czasDoOdpoczynku
- czasDrzemki
- asystentŚwiateł
- asystentPasówBezpieczeństwa
- asystentOdpoczynku
- asystenci
Hierarchiczna struktura pozwala na przekazanie do poszczególnych komponentów jedynie sekcji zawierającej ustawienia przypisane do wybranej aplikacji. W ten sposób skracamy efektywnie czas aplikowania konfiguracji, ponieważ odbiorca nie musi przeszukiwać całego drzewa ustawień, a jedynie niewielki jego fragment.
Cały proces ładowania ustawień można przedstawić następującym schematem: